This past Friday, my colleagues Navi and Aryan and I presented a demo at the Rare Disease AI Hackathon organized by Research To The People and Stanford Medicine. We built a tool called the Rare Disease Navigator, which lets patients of Ehlers-Danlos Syndrome (EDS) and Hypophosphatasia (HPP) find and understand medical papers related to their condition. The tool is hosted at https://raredisease.health/ and you should give it a crack right now!
Why We Did It
Several members of our team have nebulous and chronic health issues and have found it frustrating to deal with the medical system the way it’s currently set up. This is especially true for rare disease patients who may face several years of skepticism before receiving a proper diagnosis. Even after diagnosis, they may find it hard to access qualified medical care in their immediate vicinity. As a result, many patients find themselves having to survey and understand the medical literature so that they don’t simply fall through the cracks. Patient advocacy groups such as Research to the People are looking into ways that generative A.I. can be used to make life easier for patients, their families and the practitioners who serve them. Participating in this hackathon not only gave us an opportunity to try to make a contribution but also to pick up and use some current generative AI tools and techniques. Specifically, we want to build something could be refined into a concrete product at a low cost and with immediate benefit. Since ChatGPT is used widely and has been beneficial to so many people, we wanted to build something complementary to it instead of reinventing it.

What We Tried First
The hackathon organizers provided us with a large number of EDS and HPP academic papers along with knowledge graphs pertinent to both conditions from QIAGEN. We loaded up the papers into a document store (Elasticsearch), the content from the papers as text embeddings into a vector database (Pinecone) and, finally, the knowledge graphs into a graph database (Neo4J). We then tried various forms of retrieval-augmented generation (RAG) using the loaded data such that we combined putative patient queries with relevant information to fetch a response from a combination of large language models. We also tried to create a purpose-built language model for the two rare diseases by fine-tuning an open source LLM, i.e. Meta-Llama-3-8B-Instruct, with text from the provided papers using HuggingFace’s AutoTrain.

What Didn’t Work
While manually obtaining matches for user queries from the vector database returned promising lists of papers or their contents, programmatically incorporating the same information into queries to large language models using RAG was underwhelming. We did not have a single “aha” moment and even when sometimes attaching citations or adding context seemed to provide some value, it wasn’t worth the cost of running the language model for each user query. Absent current data from an electronic healthcare record system or some sort of real-time feed of live data, RAG seems neither appropriate nor promising for this domain. Since we only fine-tuned a “small” eight billion parameter model, its output simply couldn’t compete with responses from off-the shelf “larger” models with seventy billion parameters such as Meta-Llama-3-70B-Instruct. Without access to high-quality data vetted for relevant and accuracy by rare disease patients and practitioners, it seemed irresponsible to spend the funds and energy needed to fine-tune such large models. The knowledge graphs could have been used for RAG or to improve product UX but a detailed look at the contents showed that the data from natural language processing techniques for inferring concepts and their relationships from the academic papers was often incorrect, even when the graph indicated absolute (100%) confidence for many entries.

What Did Work
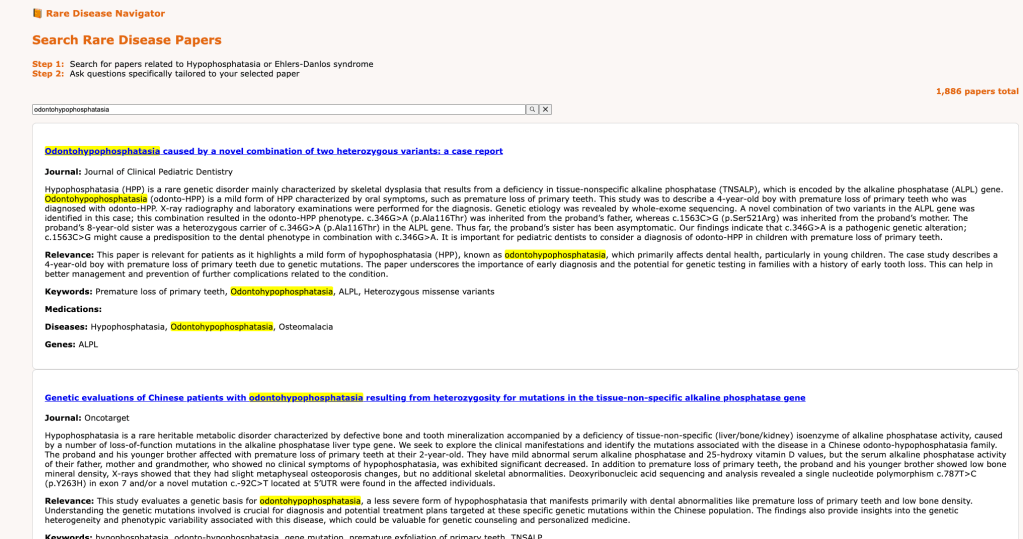
Once we inverted our approach to help users select academic papers they care about and then help them process and understand them, we were able to deliver an affordable and useful user experience. At a cost of around $100 and little energy expenditure, we were able to use Mistral’s Large model to process 1,886 EDS and HPP papers to extract semantic information such as journal name, abstract, relevance to patients, and applicable keywords, medications, genes and diseases, which we stored in MongoDB for easy retrieval. This upfront one-time invocation of an LLM let us build a searchable index using Algolia’s search-as-a-service to build our final product. The model not only produced accurate and accessible semantic information but also formatted it conveniently in the correct JSON format (with some prompt engineering) for storage into a database. Once users focus on an individual paper, the semantic information provides a focused and rich context for designing prompts which answer the user’s questions. In fact, the extracted concepts were accurate and comprehensive enough that an implicit knowledge graph can be constructed out of them.

Impressions At Large
On demo day, we observed multiple teams from industry and academia apply standard RAG and fine-tuning approaches to generally build ChatGPT-like interfaces for EDS and HPP. While it is good to first apply standard techniques to new domains, we are skeptical that these approaches will really help with patient advocacy or the search for cures. The fine-tuned models were generally based on off-the-shelf models with much smaller numbers of parameters compared to GPT-4 and GPT-4o which ChatGPT uses so patients and practitioners are better off sticking to the latter. The benchmarking techniques teams used to validate these models can easily be gamed and should not be trusted until medical LLMs have open, well-respected benchmarks suitable for medicine and healthcare, e.g. Scale’s private AI benchmarks for general LLM performance. The RAG techniques involve shoehorning the available data into a cookie-cutter techniques instead of identifying or creating datasets which can lead to better patient outcomes. Suffice to say, ChatGPT and its brethren will remain the best tools for patients for a while.
Lessons for the Future
This edition of the hackathon was quite useful for validating many off the shelf AI techniques in the zeitgeist for rare disease. For the future, everyone should pay careful heed to what doesn’t turn out to work. Most importantly, patients, advocates and clinicians should use the current projects as a baseline, evaluating them thoroughly to understand their limitations and promises so that the next edition of the hackathon can be done with their active participation, both in putting together rich datasets and benchmarks and also for directly driving the products that are built. We were impressive by the prototype for Omacare, which helps caregivers look for local healthcare resources and navigate the system, precisely because it was informed by patient’s families needs and real-world frustrations with the system. This approach to applying generative AI will be key to serving the rare disease community in the future.
What We Learnt
If we were to do another rare disease AI hackathon, I would stick to some basic lessons which I have learned in other domains as well in the past. The data is preeminent in the hacking process and everything follows from it. It’s best to quickly load up the data in the simplest possible tools, e.g. Excel or Sqlite or MongoDB, and simply examine it and play with it for as long as possible. After gaining some intuitions about the structure and quality of the data, it’s best to hack up a working prototype in the most mininal possible test bed, in this case a Jupyter notebook or two. Finally, for niche domains, it’s useful to always keep real-world constraints in mind, e.g. compute costs, paucity of vetted and high quality datasets, energy consumption, as they can indirectly clarify the direction of the product.
Shout Outs
Overall, the hackathon was really well organized and demo day drew a packed audience at GitHub HQ in San Francisco with teams from multiple countries and specializations. Among the attendees was Anna Brockman, an EDS patient, along with her husband Greg of OpenAI fame. Considerable effort had obviously gone into putting together all the data provided to us and there was an open and collaborative atmosphere throughout the weeks leading up to demo day. We are really thankful to Jessy Reyes González, Pete Kane and the rest of the team for giving us the opportunity to work on such an interesting problem and letting us meet brave, smart and motivated rare disease patients who are moving mountains in Silicon Valley so the rare disease community all over the world may one day reap the benefits of generative AI.
(This project was built under the aegis of Recherché Labs.)

Leave a comment